Библиотека Pandas предоставляет доступ ко множеству функций, которые могут понадобиться при анализе данных при помощи Python, однако сегодня мы поговорим о 10 функциях, которые должен знать каждый уважающий себя аналитик, использующий Pandas.

Перед работой с функциями Pandas не забываем импортировать эту библиотеку:
import pandas as pd
1. read_csv()
Функция read_csv() позволяет получить данные из файла формата csv, не используя каких либо сторонних библиотек. Все, что вам нужно сделать – это указать путь до файл. Важно отметить также и то, что данные можно получать как с локального диска, так и из сети Интернет(!). Ниже пример загрузки csv файла c Google диска:
url='https://drive.google.com/file/d/1KXfupiJKql5Lc-D73KiiS_jEd_CNIW44/view?usp=sharing'
url2='https://drive.google.com/uc?id=' + url.split('/')[-2]
df = pd.read_csv(url2)

Полученные данные автоматически преобразуются в Dataframe с которым мы и будем работать в дальнейшем.
2. head(), tail()
Функция head() позволяет просмотреть первые пять строк в Dataframe. Вы также можете указать в скобках то количество строк, которые вы хотели бы отобразить с начала Dataframe. Функция tail() работает аналогично, но только вместо первых строк, она показывает последние:df.head(3)
df.tail(3)

3. info()
Функция info() предоставляет суммарную информацию о вашем Dataframe. Вы получите информацию о количестве строк, наименовании столбцов, количестве непустых строк в них, типе данных в каждом столбце, а также столько памяти занимает Dataframe:df.info()

4. describe()
Функция describe() для каждого числового столбца, в случае нашего примера это столбец Rating, выводит основные описательные статистические данные, такие как минимум, максимум, распределение по долям:
df.describe()

5. dtypes
При работе с данными в столбцах, нам необходимо понимать какой формат у этих данных и если Pandas при создании Dataframe неправильно присвоил тип данных столбцу, мы могли бы его в дальнейшем исправить. Функция dtypes() отображает тип данных (обратите внимание, что круглые скобки этой функции при работе в Dataframe не нужны):df.dtypes

6. astype()
Функция astype() позволяет изменить тип данных у столбца в случае, если тип данных некорректный. Для примера воспользуемся примером из одного из предыдущих уроков:
city_data = {
'Город':['Москва', 'Казань', 'Владивосток', 'Санкт-Петербург', 'Калининград'],
'Дата основания':['1147', '1005', '1860', '1703', '1255'],
'Площадь':['2511', '516', '331', '1439', '223'],
'Население':['11,9', '1,2', '0,6', '4,9', '0,4'],
'Погода':['8', '8', '17', '9', '12'] }
city_df = pd.DataFrame(city_data)
city_df.dtypes
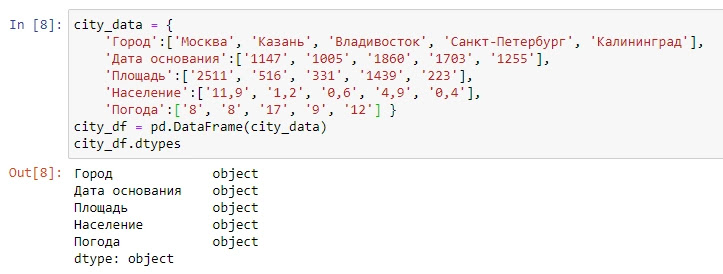
Как вы видите, у столбца Погода тип данных object, хотя в нем вся информация цифровая, давайте переведем его в формат int64:
city_df['Погода'] = city_df['Погода'].astype('int64')

После преобразования данные в столбце «Погода» стали восприниматься Pandas как int64 и соответственно с ними теперь можно проводить математические операции.
7. sample
Функция sample(n=…) отображает n случайных строк из Dataframe. Великолепная функция, если вам надо ориентировочно понять, что именно содержится в вашем Dataframe. Параметр n отвечает за то, сколько строк необходимо показать:df.sample(n=10)

8. drop_duplicates()
Функция drop_duplicates() удаляет дубликаты в наших данных (параметр inplace=True означает, что мы изменяем исходный Dataframe):
df.drop_duplicates(inplace=True)

9. Isna()
Функция Isna() возвращает информацию о том, есть ли в вашем Dataframe столбцы с пропущенными данными:df.isna().any()

В нашем примере в столбцах Rating, Type, Content Rating, Current Ver, Android Ver есть строки, в которых отсутствуют какие-либо данные.
10. loc[:]
Функция loc позволяет получить данные из выбранных строк и столбцов. В качестве строк необходимо указать номера строк, которые необходимо отразить, а в качестве столбцов – их наименования. К примеру, со второй по четвертую строку получим наименования приложений и их рейтинг:
df.loc[1:3,['App', 'Rating']]

Хитрость: Используя данную функцию, можно получить данные из конкретной ячейки, указав ее строку и столбец.
Спасибо, за то, что прочитали статью. В ней я хотел рассказать о 10 нужных функциях Pandas при анализе данных, которые должен знать каждый.
В качестве бонуса, как обычно, я прикладываю ноутбук с примерами из этой статьи.
0 comments:
Отправить комментарий
Спасибо за комментарий.